Malayalam Related Topics
[See instructions to install an old orthography Malayalam Unicode font which is required to read the posts below]Unicode: virama model Vs subjoined model - by Eric Muller
Copied from Indic Mailing list Archive[username=unicode-ml password=unicode]
This message is motivated by UTC agenda items for Myanmar,
one of which, taken literally, asks for the encoding of subjoined
characters in what is a virama model.
The distinction between the virama model and the subjoined model is often
seen as the source of the dissatisfaction of some of our users. In my
opinion, it is only a secondary issue, that is not enough to explain
that those users keep coming back. There is a primary issue that we
not yet identified, and therefore cannot address. It is that primary
issue that we need to find.
I am not sure what the primary issue is. I have a candidate and the
rest of this document is an attempt at describing this candidate. It
is quite possible (and even likely!) that I am entirely wrong; that
does not matter - what matters is that we look for this primary
issue. While I try to be precise and factually correct, there are
certainly intentional white lies and ommisions, and arbitrary
simplifications; forests and trees, as they say. If you give up on
reading this, please read the last paragraph anyway.
---
The starting point of the Indic scripts is an inventory of
letters. There is a bunch corresponding to vowel sounds: a, a:, i, i:,
u, u:, etc. There is a bunch corresponding to consonant sounds: ka,
kha, ga, ... At this point, we don't distinguish the dependent and
independent forms of vowels, we have a single "a" in our inventory.
In Latin based writing systems, we also have an inventory of letters
(a, b, c, d, etc). A written word or even a whole text reflects
directly a sequence of those letters. There may be ligatures, but once
you have a sequence of letters and just that, you can legibly render
that word: for each letter, take its letterform, put it at the end of
the line assembled so far.
For Indic scripts, the sequence of letters is not enough: in addition,
you need to know how to segment it. The rendering is: for each
segment, build its letterform, put it at the end fo the line assembled
so far. Of course, the segments I am speaking about are the "aksaras"
or something close to that. They are typically a few letters in size
(say, 1 to 5).
The letterform for a segment of course reflects somehow the letters in
that segment. In some cases, it is a letterform unique to that
sequence of letters, where it is not possible to match a fragment of
the letterform with any of the letters in the segment. In other cases,
some of the letters (but not necessarily all) can be identified with
fragments of the letterform. Yet in another cases, the letterform is
obtained by a rather straightforward combination of the letters. These
are not rigid categories: there is a continuum from the "unique shape"
to the "straighforward assembly"; that explains why we end up with a
bunch of exceptions every time we try to come up with rigid
categories. (This also says that, in my opinion, any formalization in
the encoding of those categories is bound to failure.)
When fragments of the letterform for a segment can be identified with
letters of that segment, then we can observe that they are arranged
with a lot of freedom: the fragment for the first letter may end up on
the far right, the fragment for the last letter may end on the far
left, a letter in the middle may end with multiple disconnected
fragments all over the place. Within a segment, everything goes. On
the other hand, there is essentially no typographic interaction
accross segments. That's why I like to call the segments "typographic
clusters".
To me, it is this basic inventory of letters and this concept of
typographic clusters that characterize first and foremost the Indic
scripts, and survives more or less accross all the historical
transformations and adaptations of the scripts.
So far, we have not discussed at all how the typographic clusters are
determined. In the Sanskrit/Devanagari case, a typographic cluster
corresponds to a /c_1...c_n v/ sound sequence (i.e. some consonants
followed by a vowel), where the /v/ sound is typically not written if
it is the inherent vowel sound /a/ the script. The sequence of letters
in the typographic cluster will therefore be of the form "[c_1...c_n
v?]". Because the vowel letter is optional, we need some way to
disinguish the two cluster text "[c_1] [c_2 v_2]" (which writes more
or less the sounds /c_1, a, c_2, v_2/) from the one cluster text "[c_1
c_2 v_2]" (which writes more or less the sound /c_1, c_2, v_2/).
We have two encoding models to do that:
- virama model : encode a single coded character per consonant letter,
encode a combining coded character for each vowel letter, encode a
consonant linking coded character, V. Then the typographic cluster
"c_1...c_n v" is represented by the sequence of coded characters "c_1
V ... V c_n v_combining", i.e. we stick the V consonant linking coded
character between the consonants of a cluster. Now we know that "c_1
c_2 v_combining" is segmented "[c_1] [c_2 v]" while "c_1 V c_2
v_combining" is segmented "[c_1 c_2 v]".
- subjoined model : encode two coded charaters per consonant letter,
one non-combining and one combining, encode a combining coded
character for each vowel letter; the cluster "c_1 ... c_n v" is
represented by the sequence of coded characters "c_1_non_combining
c_2_combining ... c_n_combining v_combining". Now we know that
"c_1_non_combining c2_non_combining v2_combining" is segmented "[c_1]
[c_2 v2]" while "c_1_non_combining c_2_combining v_combining" is
segmented "[c_1 c_2 v_2]".
In both cases, we also have a non combining coded character of the
vowels, to mark those clusters which have no consonants.
It should be clear that these two encoding models are just technical
variations, really two serialization schemes to go from a sequence of
typographic clusters to a sequence of coded characters; somehow we
need some way to retain the segments in what is otherwise just a
sequence of coded characters, hence the additional coded
characters. We could dream of other serializations; for example, instead
of having separate combining and non-combining vowels we could use our
V linker: "[v] [cv]" would be "v c V v" instead of our traditional
"v_non_combining c v_combining".
Since the two models are a priori equally viable, which one gets used
depends on factors such as the precedent set by other encoding
standards (and do we have a third model, the visual model,
because of that, but we ignore it here). Another factor is the way the
users of the script look at it, which is more or less aligned with the
way the letterform for a cluster is built: for example, if we can
systematically recognize in it the standalone letterform of the first
consonant and deformations of the letterforms of the remaining
consonants, this matches well with a subjoined model.
If the two models are equally viable, why do we get so many fights on
which one to use? Surely, the native writers can see through that; yet
no matter how often we repeat that it should not matter, they keep
coming back.
One interpretation is that they can't accept a less-than-perfect match
between the encoding model and the way they look at their script. Take
Myanmar: the second consonant of most clusters is the one that takes a
so-called medial form, they learn those medial forms as separate
entities, and they get surprised when this does not directly translate
in the encoding of medial forms.
This is a plausible interpretation, but I don't think it is enough to
explain the insistance of the users to change the encoding model. I
personally trust that they are smart enough to realize that "V ya"
vs. "ya_combining" does not make that much of a difference, and that
*changing* the existing encoding is far more damaging than the
gain. There has to be something else to motivate their requests.
In looking at the Myanmar document L2/04-273 (which proposes what
amounts to four subjoined consonants in a virama model), I was really
intrigued by their examples of representation on page 10. Look at the
string of coded characters "70 bytes", i.e. the current Unicode
representation. In two cases, they write the virama coded character as
"V"; in the other cases, they mark it as "". It is the same coded character in all
cases, why do they make a distinction? They could have used "V"
everywhere or "" everywhere, the point they are making does not
truly depend on that distinction. One observation is that they use
"" when the typographic clustering is indicated visually by this
hook, and "V" when the typographic cluster is indicated visually by
modification of the consonants. May be they don't think of those two
uses of the virama coded character as equivalent (hence the desire to
distinguish more strongly those uses in the encoding).
In looking at a random piece of text in Myanmar, one has to be struck
by the frequency of the visible virama sign. In Hindi/Devanagari, a
visible virama is fairly rare. In fact, that should be expected: a
visible virama essentially appears when the letterform of a
typographic cluster is at its "lowest" and least desirable form, with
multiple individual consonants in their standalone form, and the
visible virama serves to indicate that they form a single cluster.
One could say that the whole point of typographic clusters is to avoid
those cases, hence their low frequency in practice. (This also explains
why the occasional attempts at reform that result in increasing the
frequency of visible viramas, may be driven by technology limitations,
seem to fail so miserably).
So what about Myanmar? The syllabification of Myanmar is strongly
either (C(C)V) or (C(C)VC); they say that they have open (ending in a
vowel) and closed (ending in a consonant) syllables. The observation
is that the visible virama occurs essentially on the final consonant
of closed syllables. If you take a fictive word like "pur-ti", its
written form shows those two syllables: the "r" is not allowed to
interact typographically with the following "ti", so you end with
"..., ...". By contrast, in
Hindi/Devanagari, the same syllabification is not reflected in the
written form, the "r" is allowed to interact with the "ti", as you
would expect from this typographic cluster; and interact it does,
since visually you have "p_uitr". In short, Hindi/Devanagari does not
care to reflect the syllables in the written form, Myanmar does, and
that is achieved by a high use of visible viramas.
Hyphothesis: the real typographic clusters of Myanmar are not [c_1,
.., c_n, v], they are the syllables. That is the segment were
typographic interaction occurs. Our encoding of Indic scripts imposes
[c_1, ..., c_n, v] clusters and that is were the discomfort is, not in
how a cluster is encoded (virama or subjoined). All the attempts at
modifying the encoding are first and foremost attempts to make the
real typographic clusters surface, but since the two alternatives for
encoding are fundamentally equivalent, they fail.
I don't have any "proof" of that hypothesis. All I can say is that if
you start with "The authors of L2/04-273 want to tell us that they
have different typographic clusters; forget the virama/subjoined
battle, it is just noise", then their discourse, and the progression
of their argument becomes much more meaningful. If instead you read it
as "The battle is about virama/subjoined", then the document seems
just like another silly attempt.
It is also interesting to remember the Devanagari eyelash ra. From
what we gathered, in Nepali/Devanagari, there is a desire to
graphically convey whether a ra is the final of a syllable or the
initial of the next. The typographic clusters of "pur-ti" are "[pu]
[rti]", while the typographic clusters of "pu-rti" are "[pur]
[ti]". The graphic device used here is different from what Myanmar
does (because the typographic clustering is the *opposite* of the
syllable clustering), but the overall goal is the same: reflect
syllables in the written form, by constraining the typographic
clusters.
One could also wonder whether the Malayalam chillus are not yet
another manifestation of this: a graphic device to reflect in writing
the syllabification by constraining the formation of typographic
clusters.
---
Is this theory correct? If so, how do we use it? As I said, I don't
care to be the person who will identify the precise disconnect with
our users, but I am pretty sure it is more than virama vs. subjoined, and
I think it's important we find it and fix it. That is the point of
this contribution.
Eric.
Unicode: Malayalam Chillu: Discussion Index
Based on Rachana Document
Bottom Line
- Confusing Code points as base characters
- Fallacy of section 3
- Serious omisson in section 4
- History and current status of Samvruthokaram - it isn't what Rachana says
- Collation is a non-issue with encoding chillu
- One chillu is already encoded years back
- Half forms are not chillus
- ZWJ shouldn't be overloaded for searching
- Unanswered questions
Bottom Line
Unicode: Chillu: Confusing code points as base characters
Rachana has a genuine concern that by encoding chillus we are giving them charater status. That is not true. Code points are not base characters. This is a kind of explained in Character Encoding Model.
Regarding the collation, Rachana states:
Regarding the collation, Rachana states:
"Only when two characters or sequences differ in [collation] value (or weight) at the primary level, is there a need to differentiate them at the encoding level."This is also not true. See this:
- Eventhough, English lowercase and uppercase characters are encoded seperately, they differ only in tertiary level in Default Unicode Collation Element Table (DUCET). See UTS#10.
- There are lot of codepoints without any primary weight. An indic example would be Visarga.
Unicode: The Chillu Challenge
Abstact
It is proved thru a counter-example.
If Chillu-C1 + C2 is equivalant to C1 + Virama + C2, provide different unicode representations for the following two malayalam words:
If there is no solution, that would indicate that Chillu-C1 + C2 is not equivalant to C1 + Virama + C2 and the current chillu representation in Malayalam Unicode is flawed; thus making the section 3 of Rachana document incorrect.
In other words, the half-form (notation of vowellessness) of C1 is not same as chillu-C1.
Why should they have different encodings?
The words /pin_nilaavum/ and /pinnilaavum/ are different in all 3 essential attributes of a word:
The difference should be in some non-joiner characters
See pages 389 to 391 in chapter 15 of Unicode 4.0.0
More examples
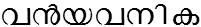 /van_yavanika/ meaning 'big curtain'
/van_yavanika/ meaning 'big curtain'
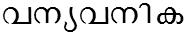 /vanyavanika/ meaning 'wild forest'
/vanyavanika/ meaning 'wild forest'
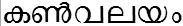 /kaN_valayam/ meaning 'eye boundary'
/kaN_valayam/ meaning 'eye boundary'
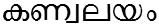 /kaNvalayam/ meaning 'peace of Kanvan - the mythical character'.
/kaNvalayam/ meaning 'peace of Kanvan - the mythical character'.
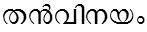 /than_vinayam/ meaning 'his/her modesty'
/than_vinayam/ meaning 'his/her modesty'
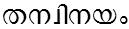 /thanvinayam/ meaning 'policy of a woman'
/thanvinayam/ meaning 'policy of a woman'
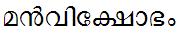 /man_vikshObham/ meaning 'explosion of mind'
/man_vikshObham/ meaning 'explosion of mind'
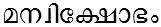 /manvikshObham/ meaning 'fury of a lady'
/manvikshObham/ meaning 'fury of a lady'
General patterns of these examples are (both the forms of character capable of forming chillu) + (semi-vowels) and (ന in chillu or pure form) + ന. Above examples are just few from vast number possible with these pattern rules.
Counter-challenge from Kenneth Whistler
If separate characters are encoded for Malayalam Chillus, so that the "challenge" distinction were to be encoded as:
"nn" is U+0D28, U+0D4D, U+0D28
"n_n" is U+0DXX, U+0D4D, U+0D28
implementers are then faced with determining what to do with the following sequence:
"???" is U+0D28, U+0D4D, U+200D, U+0D28
That sequence, of course, exists now, and would be a legitimate and possible sequence even if a Chillu-n is encoded. So how would a rendering engine render that sequence, and how would
it be distinguished, by an end user or a text process such as a search engine, from the proposed U+0DXX, U+0D4D, U+0D28 sequence for "n_n"?
That counter-challenge needs a "solution" for the encoding of Chillu characters to make sense for Malayalam. For if there is no solution forthcoming, addition of Chillu characters would potentially be *increasing* the ambiguity potential for the Unicode representation of Malayalam text, rather than decreasing it.
Solution to Ken's challenge
Half-form of NA (ന) is not chillu. It is described in detail here.
Now, we can use the rules in ZERO WIDTH JOINER in Indic Scripts standard to see the behavior of the challenge sequence. It will form the conjunct double ന്ന /nna/ as per the second bullet in the section 7-proposal of above pr#37.
- Chillu-C1 + C2 is not equivalant to C1 + Virama + C2, in contrast to Rachana's claims.
- Chillu issue is has an existance independant of Samvruthokaram confusion
It is proved thru a counter-example.
If Chillu-C1 + C2 is equivalant to C1 + Virama + C2, provide different unicode representations for the following two malayalam words:
- /pin_nilaavum/
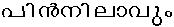
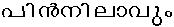
- /pinnilaavum/

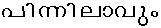
If there is no solution, that would indicate that Chillu-C1 + C2 is not equivalant to C1 + Virama + C2 and the current chillu representation in Malayalam Unicode is flawed; thus making the section 3 of Rachana document incorrect.
In other words, the half-form (notation of vowellessness) of C1 is not same as chillu-C1.
Why should they have different encodings?
The words /pin_nilaavum/ and /pinnilaavum/ are different in all 3 essential attributes of a word:
- Meaning. /pin_nilaavum/ means 'and shadow of moonlight'. /pinnilaavum/ means 'will be behind'
- Pronounciation. The second 'na' of /pinnilaavum/ is an alveolar and that of /pin_nilaavum/ is dental.
- Orthography. The first 'na' of /pin_nilaavum/ is chillu while we have the conjunct double of 'na' in /pinnilaavum/.
The difference should be in some non-joiner characters
See pages 389 to 391 in chapter 15 of Unicode 4.0.0
"ZERO WIDTH NON-JOINER and ZERO WIDTH JOINER are format control(thanks to Mahesh Pai)
characters. Like other such characters, they should be ignored by
processes that analyze text content. For example, a spelling-checker
or find/replace operation should filter them out. (See Section 2.11,
Special Characters and Noncharacters, for a general discussion of
format con- trol characters.)"
More examples
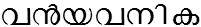 /van_yavanika/ meaning 'big curtain'
/van_yavanika/ meaning 'big curtain'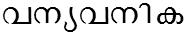 /vanyavanika/ meaning 'wild forest'
/vanyavanika/ meaning 'wild forest'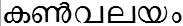 /kaN_valayam/ meaning 'eye boundary'
/kaN_valayam/ meaning 'eye boundary' /kaNvalayam/ meaning 'peace of Kanvan - the mythical character'.
/kaNvalayam/ meaning 'peace of Kanvan - the mythical character'. /than_vinayam/ meaning 'his/her modesty'
/than_vinayam/ meaning 'his/her modesty'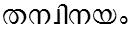 /thanvinayam/ meaning 'policy of a woman'
/thanvinayam/ meaning 'policy of a woman' /man_vikshObham/ meaning 'explosion of mind'
/man_vikshObham/ meaning 'explosion of mind'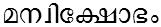 /manvikshObham/ meaning 'fury of a lady'
/manvikshObham/ meaning 'fury of a lady'General patterns of these examples are (both the forms of character capable of forming chillu) + (semi-vowels) and (ന in chillu or pure form) + ന. Above examples are just few from vast number possible with these pattern rules.
Counter-challenge from Kenneth Whistler
If separate characters are encoded for Malayalam Chillus, so that the "challenge" distinction were to be encoded as:
"nn" is U+0D28, U+0D4D, U+0D28
"n_n" is U+0DXX, U+0D4D, U+0D28
implementers are then faced with determining what to do with the following sequence:
"???" is U+0D28, U+0D4D, U+200D, U+0D28
That sequence, of course, exists now, and would be a legitimate and possible sequence even if a Chillu-n is encoded. So how would a rendering engine render that sequence, and how would
it be distinguished, by an end user or a text process such as a search engine, from the proposed U+0DXX, U+0D4D, U+0D28 sequence for "n_n"?
That counter-challenge needs a "solution" for the encoding of Chillu characters to make sense for Malayalam. For if there is no solution forthcoming, addition of Chillu characters would potentially be *increasing* the ambiguity potential for the Unicode representation of Malayalam text, rather than decreasing it.
Solution to Ken's challenge
Half-form of NA (ന) is not chillu. It is described in detail here.
Now, we can use the rules in ZERO WIDTH JOINER in Indic Scripts standard to see the behavior of the challenge sequence. It will form the conjunct double ന്ന /nna/ as per the second bullet in the section 7-proposal of above pr#37.
Unicode: Chillu: why not encode a diacritic tail
Essentially, what I have shown in the challenge is that the issue of (chillu ? chandrakkala) is not a derivative of the issue of (chandrakkala ? samvruthokaaram). These issues have to be tackled separately. So I am taking (chillu ? chandrakkala) alone now.
In the challenge, the words differ precisely in /nn/ and /n_n/ location. We know, in the phoneme space they are different. That is, dental ന + dental ന and alveolar ന + dental ന. How is this distinction is indicated in orthography? Before explaining that, let us look at chandrakkala once more.
Chandrakkala when used for vowellessness, is acting as a language specific control character. It removes the default 'അ' from the consonant behind it. That is, it is acting as an attribute remover.
It is the property of any vowelless consonant to get help from the consonant next to it as if that is a vowel and thus creating a conjunct. In /n_n/, this specific property is prevented. That is how alveolar n and dental n can stay close without conjunct forming transformations. How are we denoting the removal of this conjunct creation property? Are we using any specific symbols to indicate this? In fact, yes. It is a vertical tail across the letter.
Since chandrakkala exist as a separate orthographic entity detached from the letter, we can easy see its functionality. In contrast, conjunct creation preventer symbol get embedded in the orthography of a letter and that makes it difficult to recognize it.
So my conclusion (not a solution) is this: an malayalam specific control symbol, different from chandrakkala, is present in a chillu letter. Its functionality is 1) remove the inherent അ vowel 2) then prevent the consonant from forming deep conjunct with the next letter. If we recognize, the function (1) alone, we will not solve the riddle of chillu.
This symbol could be encoded as level-1 ignorable in the collation table, as most of the diacritic marks.
In the challenge, the words differ precisely in /nn/ and /n_n/ location. We know, in the phoneme space they are different. That is, dental ന + dental ന and alveolar ന + dental ന. How is this distinction is indicated in orthography? Before explaining that, let us look at chandrakkala once more.
Chandrakkala when used for vowellessness, is acting as a language specific control character. It removes the default 'അ' from the consonant behind it. That is, it is acting as an attribute remover.
It is the property of any vowelless consonant to get help from the consonant next to it as if that is a vowel and thus creating a conjunct. In /n_n/, this specific property is prevented. That is how alveolar n and dental n can stay close without conjunct forming transformations. How are we denoting the removal of this conjunct creation property? Are we using any specific symbols to indicate this? In fact, yes. It is a vertical tail across the letter.
Since chandrakkala exist as a separate orthographic entity detached from the letter, we can easy see its functionality. In contrast, conjunct creation preventer symbol get embedded in the orthography of a letter and that makes it difficult to recognize it.
So my conclusion (not a solution) is this: an malayalam specific control symbol, different from chandrakkala, is present in a chillu letter. Its functionality is 1) remove the inherent അ vowel 2) then prevent the consonant from forming deep conjunct with the next letter. If we recognize, the function (1) alone, we will not solve the riddle of chillu.
This symbol could be encoded as level-1 ignorable in the collation table, as most of the diacritic marks.
Unicode: Chillu: half forms are not chillus
At least, 3 of the chillu forming consonants have half-forms different from chillus. As the first example, half-na is highlighted in this image:

Notice that half-na is not chillu-na. Below, we can see the half-consonant in action forming conjuncts with various characters:

Simillar to ന(NA), ക (KA) and ണ (NNA) also have following half-forms:


Their conjunct formation examples are:

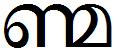
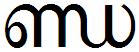
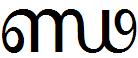

Notice that half-na is not chillu-na. Below, we can see the half-consonant in action forming conjuncts with various characters:

Simillar to ന(NA), ക (KA) and ണ (NNA) also have following half-forms:
Their conjunct formation examples are:
Unicode: Chillu: ZWJ shouldn't be overloaded for searching
Software Engineering Pragmatism
I have been in software industry for last 10 years. I know, as many of you do, this: If one entity does not have philosophical integrity, soon its minor functional variations will be interpreted differently or ignored by the developers and eventually it will be a perpetual bug in most of the software applications today or to come. You all can imagine, how much priority this Malayalam bug will get in each company's defect tracking.
To tell an example, couple of months back we faced with an issue of Unicode malayalam text getting truncated in Microsoft Outlook. After some google searches we stumbled upon this piece of information: http://www.landfield.com/usefor/1997/Aug/0142.html . Undoubtedly that would the attitude development process will take towards this special case.
I can clearly understand UTC's fondness towards ZWJ solution - it is just a one line change in the standard and chillus are history or UTC. But for Malayalam community, life with Unicode is just begun. The potential bugs in the software tools and usage diffculties (which Kevin explained) will haunt us for decades. So I would ask all to think twice before committing to overload ZWJ with language specific functions.
I still wonder what Arabic community was thinking when they allowed this to happen for them. Taking Arabic as an example, soon ZWJ will get overloaded many such language specific functions and this simple ZWJ will turn into the most unscrupulous codepoint in entire standard.
I have been in software industry for last 10 years. I know, as many of you do, this: If one entity does not have philosophical integrity, soon its minor functional variations will be interpreted differently or ignored by the developers and eventually it will be a perpetual bug in most of the software applications today or to come. You all can imagine, how much priority this Malayalam bug will get in each company's defect tracking.
To tell an example, couple of months back we faced with an issue of Unicode malayalam text getting truncated in Microsoft Outlook. After some google searches we stumbled upon this piece of information: http://www.landfield.com
I can clearly understand UTC's fondness towards ZWJ solution - it is just a one line change in the standard and chillus are history or UTC. But for Malayalam community, life with Unicode is just begun. The potential bugs in the software tools and usage diffculties (which Kevin explained) will haunt us for decades. So I would ask all to think twice before committing to overload ZWJ with language specific functions.
I still wonder what Arabic community was thinking when they allowed this to happen for them. Taking Arabic as an example, soon ZWJ will get overloaded many such language specific functions and this simple ZWJ will turn into the most unscrupulous codepoint in entire standard.
Unicode: Chillu: Rachana document: criticism of section 4
In section 4, Rachana establishes that chillu-ല is not chillu-ത. However, real issue is not with chillu-ല. It is with chillu-ര and chillu-ള, because they also are chillu-റ and chillu-ഴ, respectively.
This fact is clearly established in the formost grammar book of Malayalam: Keralapaanineeyam by A. R. Rajaraja Varma. See the relevant scan from the section peethika: 4.varnnavikaarangal below:

Possible solutions and their implications
I am considering only chillu-ര/റ right now. These thoughts are applicable to chillu-ള/ഴ as well.
Thus collation correctness of chillu forming characters to their underlying letter identity is impossible in codepoint-space without the help of sophisticated text processing at higher levels. This would in turn mean, the collation correctness is not an argument until a new solution or perspective is proposed. Till then, both the choices of encoding chillu with a control/format character or giving independant codepoint for it, have to be evaluated with respect to rest of the merits these options have.
This fact is clearly established in the formost grammar book of Malayalam: Keralapaanineeyam by A. R. Rajaraja Varma. See the relevant scan from the section peethika: 4.varnnavikaarangal below:

Possible solutions and their implications
I am considering only chillu-ര/റ right now. These thoughts are applicable to chillu-ള/ഴ as well.
- Encode this chillu as chillu-ര only. That is, only RA + VIRAMA + ZWJ will form the chillu. This would cause wrong collation ordering for words with chillu-റ. That is, /kaarr_mEgham/ from the above example will get wrong place in the collation order.
- Both RA + VIRAMA + ZWJ and RRA + VIRAMA + ZWJ form chillu-ര/റ. This gives a uniqueness rule warning: "if this scheme is allowed, a document (eg: a wiktionary.org document) written by multiple people using various inputting tools can quite possibly have different 'spellings' for a word, without reader or writer being aware of it. This can cause many problems including ineffective searches and inconsistent collation".
Thus collation correctness of chillu forming characters to their underlying letter identity is impossible in codepoint-space without the help of sophisticated text processing at higher levels. This would in turn mean, the collation correctness is not an argument until a new solution or perspective is proposed. Till then, both the choices of encoding chillu with a control/format character or giving independant codepoint for it, have to be evaluated with respect to rest of the merits these options have.
Unicode: Chillu: desired homogeneity with Anuswara
Knowingly or unknowingly we have already encoded one chillu and that is Anuswara!
This fact is described in the formost grammar book of Malayalam: Keralapaanineeyam by A. R. Rajaraja Varma. See the relevant scan from the section peethika: 4.varnnavikaarangal below:

Translation of the underlined sentence: 'Anuswara is a chillu.'
Same opinion is echoed by L. J. Frohnmeyer:

(thanks to Eric Muller and Mahesh Pai)
The history of anuswara becoming chillu is something similar to that of how vowelless ത /ta/ became chillu ല /la/. Initialy anuswara came to Malayalam along with rest of the Sankrit package. Later Malayalam started to use it as chillu മ /ma/. Essentially, malayalam anuswara should not be confused with the functions of anuswara of Devanagiri. They both are different.
A R Rajaraja varma is not infallible. However, if you want to refute his arguments, you should put forward enough evidence from academic literature. Also, you should clarify what should be the relative position of Anuswara in collation.
Current scenario can be compared to, assigning codepoints for some vowel signs and then on a later thought, encoding rest of the vowel signs as VIRAMA + ZWJ + Vowel.
So, if chillu of മ /ma/ can be encoded, then why not rest of the chillus ?
I know this argument alone is not enough for encoding rest of the chillus. But given that our options are limited, this makes the arguments to encode chillus more compelling.
This fact is described in the formost grammar book of Malayalam: Keralapaanineeyam by A. R. Rajaraja Varma. See the relevant scan from the section peethika: 4.varnnavikaarangal below:

Translation of the underlined sentence: 'Anuswara is a chillu.'
Same opinion is echoed by L. J. Frohnmeyer:

(thanks to Eric Muller and Mahesh Pai)
The history of anuswara becoming chillu is something similar to that of how vowelless ത /ta/ became chillu ല /la/. Initialy anuswara came to Malayalam along with rest of the Sankrit package. Later Malayalam started to use it as chillu മ /ma/. Essentially, malayalam anuswara should not be confused with the functions of anuswara of Devanagiri. They both are different.
A R Rajaraja varma is not infallible. However, if you want to refute his arguments, you should put forward enough evidence from academic literature. Also, you should clarify what should be the relative position of Anuswara in collation.
Current scenario can be compared to, assigning codepoints for some vowel signs and then on a later thought, encoding rest of the vowel signs as VIRAMA + ZWJ + Vowel.
So, if chillu of മ /ma/ can be encoded, then why not rest of the chillus ?
I know this argument alone is not enough for encoding rest of the chillus. But given that our options are limited, this makes the arguments to encode chillus more compelling.
Unicode: Samruthokaram grapheme: current status
Summary
There are two different sets of graphemes used samvruthokaram. Usage 1: the sign of U + chandrakkala (visible virama) Usage 2: chandrakkala (visible virama) alone. These two practices co-exist today and had been like that for at least a centuary.
Details
In Keralapaanineeyam - the formost grammar book of Malayalam - A. R. Rajaraja Varma criticizes those who argue for samvruthokaram to be written without the sign of U. This, in turn , tells us when Keralalpanineeyam was written (cir. 1896) the grapheme of samvruthokaram was an issue.


Frohnmeyer writes about this in University of Madras book printed in 1913. (thanks to Eric Muller)

Eventhough the following poem by N. N. Kakkad is printed (in 1988) in old orthography, the samvruthokaram is represented with chandrakkala (visible virama) alone.

When new orthograpy became common for printing in later years, the usage of chandrakkala alone for samvruthokaram became even more widespread. Vast majority of the printed material after ~1994 uses chandrakkala alone for samvruthokaram. As an example, see following poem by Balachandran chullikkadu (written in 1970; printed in 1996 by DC books):

Current status and brief history of grapheme(s) used for samvruthokaram is more or less accurately described by Dr. Scaria Zacharia in 1996 as a footnote description in Keralapanineeyam, centinneal edition from DC books:

Translation: "In the old Malayalam, there was no seperate grapheme to indicate samvruthokaram. It used to be written and printed as /paaTTa/(patt~) and /naaTa/(naaT~). In the second half of 19th centuary, Basel missionaries started to use chandrakkala(visibile virama) to indicate samvruthokaram (L.V.R. 1940: 329). Same words have been printed with and without samvruthokaram in Gundert's works. There is no unity in Malalayalam in the issue of grapheme for samvruthokaram. In southern Kerala, the sign of U and chandrakkala together is the grapheme for savruthokaram. However, in northern Kerala, just chandrakkala (visible virama) alone is enough."
There are two different sets of graphemes used samvruthokaram. Usage 1: the sign of U + chandrakkala (visible virama) Usage 2: chandrakkala (visible virama) alone. These two practices co-exist today and had been like that for at least a centuary.
Details
In Keralapaanineeyam - the formost grammar book of Malayalam - A. R. Rajaraja Varma criticizes those who argue for samvruthokaram to be written without the sign of U. This, in turn , tells us when Keralalpanineeyam was written (cir. 1896) the grapheme of samvruthokaram was an issue.
Frohnmeyer writes about this in University of Madras book printed in 1913. (thanks to Eric Muller)

Eventhough the following poem by N. N. Kakkad is printed (in 1988) in old orthography, the samvruthokaram is represented with chandrakkala (visible virama) alone.
When new orthograpy became common for printing in later years, the usage of chandrakkala alone for samvruthokaram became even more widespread. Vast majority of the printed material after ~1994 uses chandrakkala alone for samvruthokaram. As an example, see following poem by Balachandran chullikkadu (written in 1970; printed in 1996 by DC books):
Current status and brief history of grapheme(s) used for samvruthokaram is more or less accurately described by Dr. Scaria Zacharia in 1996 as a footnote description in Keralapanineeyam, centinneal edition from DC books:
Translation: "In the old Malayalam, there was no seperate grapheme to indicate samvruthokaram. It used to be written and printed as /paaTTa/(patt~) and /naaTa/(naaT~). In the second half of 19th centuary, Basel missionaries started to use chandrakkala(visibile virama) to indicate samvruthokaram (L.V.R. 1940: 329). Same words have been printed with and without samvruthokaram in Gundert's works. There is no unity in Malalayalam in the issue of grapheme for samvruthokaram. In southern Kerala, the sign of U and chandrakkala together is the grapheme for savruthokaram. However, in northern Kerala, just chandrakkala (visible virama) alone is enough."
Unicode: Chillu: current options
- Encode Chillus as we did for മ /ma/ and handle the issue of equivalance to the base character at higher levels of text processing.
- Encode chillus other than മ /ma/ as Consonant + VIRAMA + ZWJ by overloading the format character ZWJ with Malayalam specific secondary or tertiary level collation weight. Also, both RA + VIRAMA + ZWJ and RRA + VIRAMA + ZWJ will represent exactly same chillu. Simillarly, both LLA + VIRAMA + ZWJ and LLLA + VIRAMA + ZWJ represent same chillu. After all these, issue of correctness of the inputted text has to be handled at higher levels of text processing.
Unicode: Unaswered questions
- Isn't using CGJ a dangerous thing? Because, a document (eg: a wiktionary.org document) written by multiple people using various inputting tools can quite possibly have different 'spellings' for a conjunct or word, without reader or writer being aware of it. This can cause many problems including ineffective searches and inconsistent collation.
- My understanding about collation value of a codepoint is that it is directly tied both ways to search/sort functions. That is, searching and sorting is done using collation value and when collation values vary, search/sort can potentially give different results. Does collation value has any other purpose? If no, then by attaching search and sort meaning to ZWJ, aren't we actually adding a collation value to ZWJ? That is, ZWJ in turn becoming ZWJ + CGJ in case of chillus.
- What was the reasoning behind giving vowel signs a different codepoint? Why they weren't encoded as, say, VIRAMA + AA = sign of AA
- When do you say two words with different orthography and same meaning have two different spellings. Example: color & colour. Same way, can we say that the old and new orthography renderings of the same word, say /Sabdam/ (meaning 'sound'), qualify for two different spellings?
- What is the assumption Unicode makes about the input methods? Does it assume the input method has word lookup feature or just a basic keyboard layout or inputting each Unicode codepoint by codepoint?
Unicode: Malayalam font tester
This document is to test for common inconsistencies between Malayalam Unicode fonts. Due to the lack of any precise documentation these will fall into best practices catagory and whereever there are no common practices, I have used my best judgement. Couple of links that will help you understand the principles would be:
Unicode FAQ on Indic scripts
Uniqueness rule on Chillus
'=>' means '- this sequence generates'
'=' means 'which should be rendered as'
ന+ virama + ര => ന്ര =
ന+ virama + റ => ന്റ =
ൻ + റ => ൻറ =
മ + virama + പ => മ്പ =
ന + virama + പ => ന്പ =
ങ + virama + ക => ങ്ക =
ന + virama + ക => ന്ക =
ഴ + virama + വ => ഴ്വ =
യ + virama + ര => യ്ര =
യ + virama + ല => യ്ല =
യ + virama + വ => യ്വ =
Unicode FAQ on Indic scripts
Uniqueness rule on Chillus
'=>' means '- this sequence generates'
'=' means 'which should be rendered as'
ന+ virama + ര => ന്ര =

ന+ virama + റ => ന്റ =

ൻ + റ => ൻറ =

മ + virama + പ => മ്പ =

ന + virama + പ => ന്പ =

ങ + virama + ക => ങ്ക =

ന + virama + ക => ന്ക =

ഴ + virama + വ => ഴ്വ =

യ + virama + ര => യ്ര =

യ + virama + ല => യ്ല =

യ + virama + വ => യ്വ =

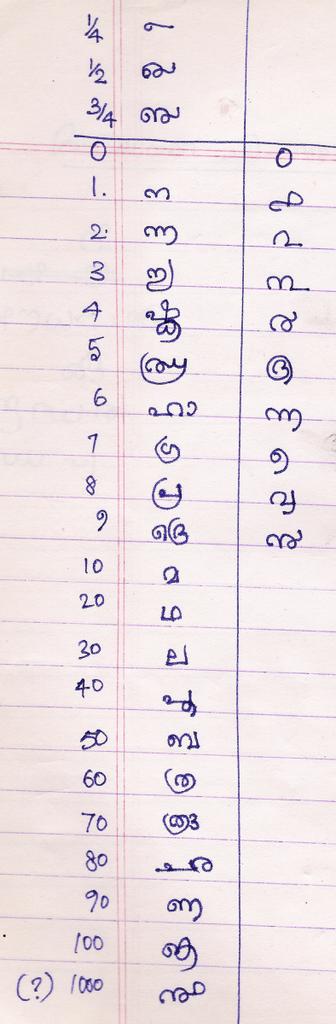
Unicode: Public Review issue #71: Malayalam Digits
 Author: Cibu C Johny
Author: Cibu C JohnyDate: Aug 29, 2005
Email: yahoo.com id 'cibu'
Please read the details of the issue at Unicode Public Review listing.
On the right, you can see the scanned image of the number symbols which I jotted down in my old note book.
Following are my suggestions for inclusion in Unicode chart:
- Shortcuts for numbers 10, 20, .., 90, 100 and 1000. These symbols are very archaic. Please see H. Gundert on this.
- The fraction symbols 1/8, 1/4, 1/2 and 3/4. My notes miss 1/8. I know there is a symbol for 1/8; but don't have a document to show how it looks. These are also very archaic. Please see this IT mission link.
- The symbol used in '17-
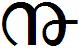 ' to mean the date '17th'. In contrast to previous ones, this date related symbol is commonly used. Many existing fonts have this in their glyph set. If at all, some of these number related symbols make it to Unicode chart, this should be the first.
' to mean the date '17th'. In contrast to previous ones, this date related symbol is commonly used. Many existing fonts have this in their glyph set. If at all, some of these number related symbols make it to Unicode chart, this should be the first.
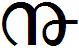
Archives
09/04 12/04 03/05 05/05 06/05 07/05 02/06 06/06 08/06
![]()